Introduction to Apache Spark - Part 4
Parts
This post is the fourth among a multi part series about an introduction to spark and how to build, run a Spark Hello World Application. Here is an index of the posts:
Part 1 - Intro and Programming Model
Part 2 - Building and running Spark applications
Part 3 - Coding up a Hello World application on Spark
Part 4 - Spark Modules - This post
Part 5 -Spark on AWS and Alternating Least Squares
Spark Modules
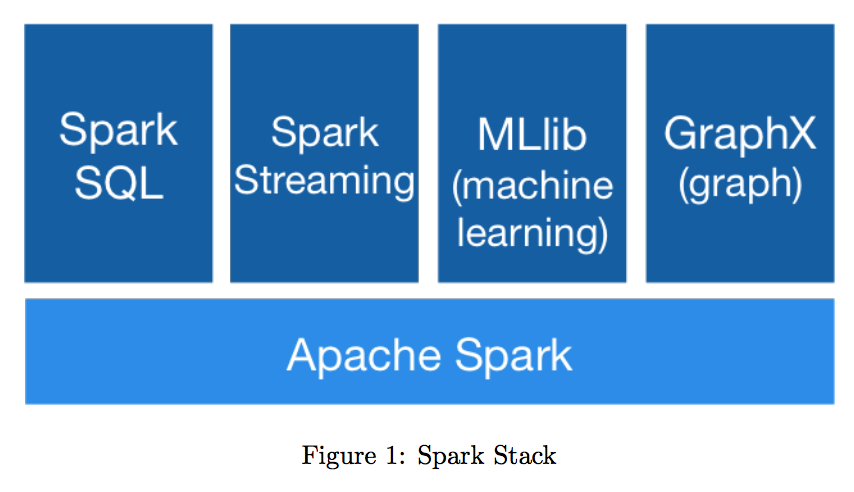
There are many popular modules which work on top of Spark as shown in Figure 1 above. Few of the prominent ones are listed and explained below:
- Spark SQL
- MLlib
- GraphX
- Spark Streaming
Spark SQL
Spark SQL is a Spark module for structured data processing. It provides a programming abstraction called DataFrames and can also act as distributed SQL query engine.
#####DataFrames A DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs.The DataFrame API is available in Scala, Java, and Python.
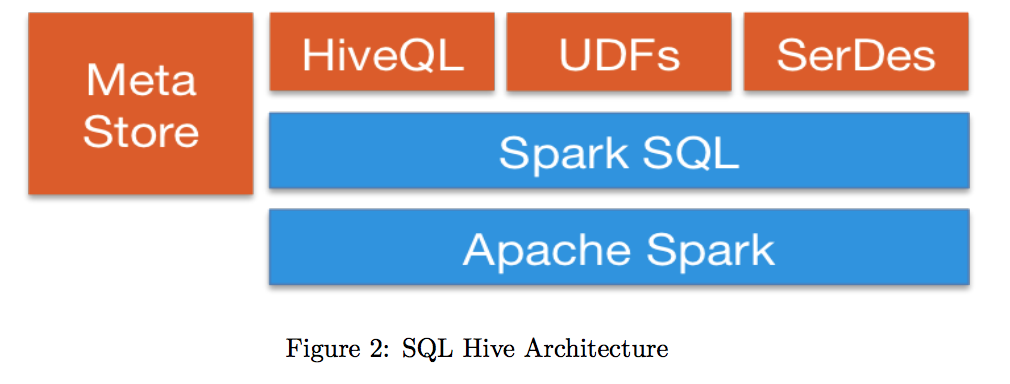
Spark SQL lets developers query structured data as a distributed dataset (RDD) in Spark, with integrated APIs in Python, Scala and Java. This tight integration makes it easy to run SQL queries alongside complex analytic algorithms. SparkSQL allows unified data access, which means that it can accept data from multiple sources seamlessly. SparkSQL is compatible with Hive, which means that Hive queries can be run on existing warehouses without any modification. Spark SQL can use existing Hive metastores, Serializer Desearializer(SerDes) and user defined funcations (UDFs) as shown in Figure 2.
MLlib
MLlib is Spark’s scalable machine learning library consisting of common learning algorithms and utilities, including classification, regression, clustering, collaborative filtering, dimensionality reduction and underlying optimization primitives. The main idea behind MLLib according to this AMPCamp talk was to make popular Machine Learning algorithms available for everyone to use in an easy manner. Spark was originally developed at the AMP Camp at UC Berkeley.
GraphX
GraphX is a new component in Spark for graphs and graph-parallel computation. GraphX extends the Spark RDD by introducing a new Graph abstraction: a directed multigraph with properties attached to each vertex and edge. To support graph computation, GraphX exposes a set of fundamental operators like subgraph, joinVertices, and aggregateMessages as well as an optimized variant of the Pregel API. In addition, GraphX includes a growing collection of graph algorithms and builders to simplify graph analytics tasks.
#####Property Graph
The property graph is a directed multigraph with user defined objects attached to each vertex and edge. A directed multigraph is a directed graph with potentially multiple parallel edges sharing the same source and destination vertex. The ability to support parallel edges simplifies modeling scenarios where there can be multiple relationships (e.g., co-worker and friend) between the same vertices. Each vertex is keyed by a unique 64-bit long identifier (VertexID). GraphX does not impose any ordering constraints on the vertex identifiers. Similarly, edges have corresponding source and destination vertex identifiers.
The property graph is parameterized over the vertex (VD) and edge (ED) types. These are the types of the objects associated with each vertex and edge respectively.
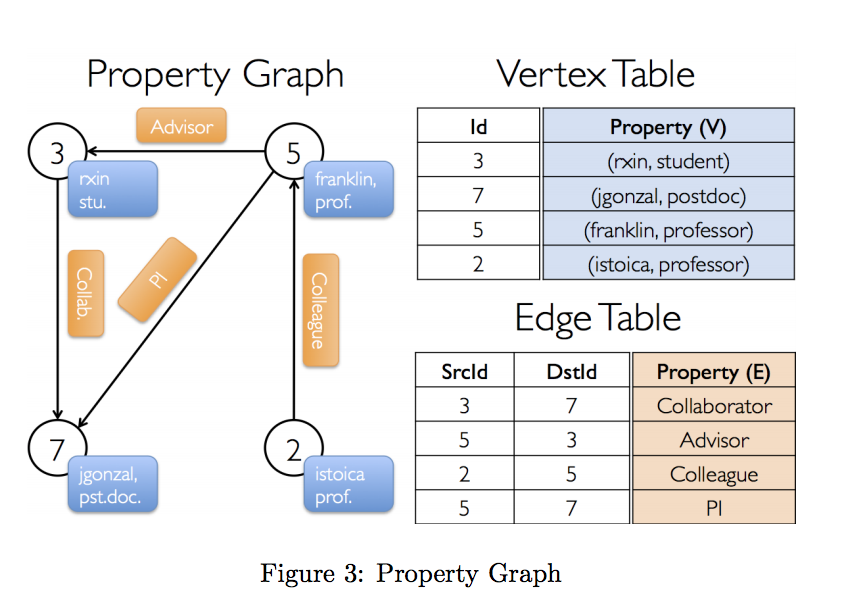
#####Example Property Graph Suppose we want to construct a property graph consisting of the various collaborators on the GraphX project. The vertex property might contain the username and occupation. We could annotate edges with a string describing the relationships between collaborators as shown in Figure 3
Spark Streaming
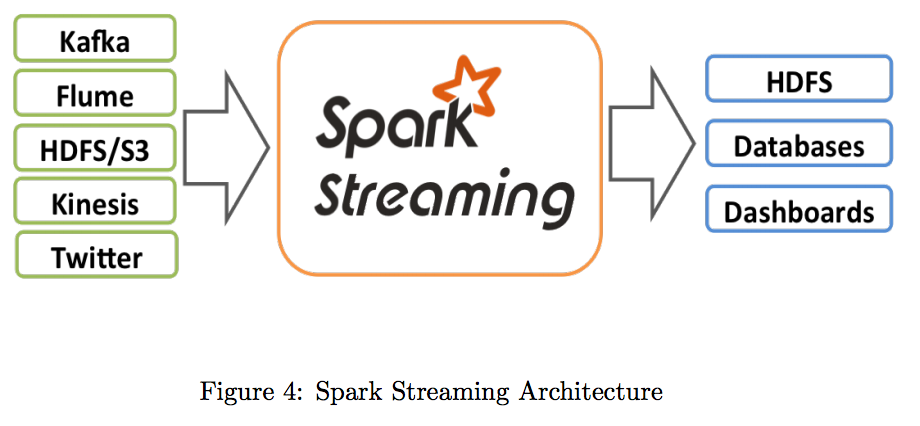
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Twitter, ZeroMQ, Kinesis or TCP sockets can be processed using complex algorithms expressed with highlevel functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards. Streaming can be used to implement Spark’s machine learning and graph processing algorithms on data streams. The architecture is as shown in Figure 4:
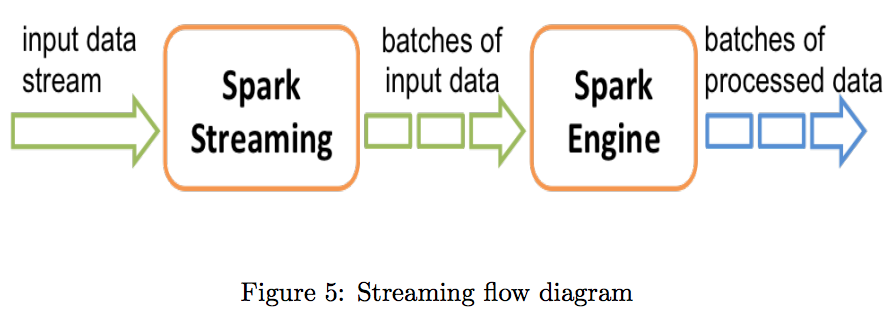
Internally, it works as follows. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches. Spark Streaming provides a high-level abstraction called discretized stream or DStream, which represents a continuous stream of data as shown in Figure 5 below. DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs.
References
- Gonzalez, Joseph E., et al. "Graphx: Graph processing in a distributed dataflow framework." Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI). 2014.
- Spark official documentation page: https://spark.apache.org/documentation.html
Figures:
Figure 1: http://spark.apache.org
Figure 2: http://spark.apache.org/sql
Figure 3: https://spark.apache.org/docs/latest/graphx-programming-guide.html
Figure 4: https://spark.apache.org/docs/latest/streaming-programming-guide.html
Figure 5: https://spark.apache.org/docs/latest/streaming-programming-guide.html