Introduction to Apache Spark - Part 5
Parts
This post is the fifth and last (for now) among a multi part series about an introduction to spark and how to build, run a Spark Hello World Application. Here is an index of the posts:
Part 1 - Intro and Programming Model
Part 2 - Building and running Spark applications
Part 3 - Coding up a Hello World application on Spark
Part 5 -Spark on AWS and Alternating Least Squares - This post
Spark on Amazon Web Services
Spark is often run on Amazon Web Services Platform with the help of it’s EC2 (Elastic Compute Cloud) machines or on the EMR (Elastic Map Reduce) service. Considering the flexibility offered by the cloud services, this is a very prominent use case. Usage of cloud based services also aids in the flexibility and easy addition of multiple instances or new machines in case the processing power is not enough for the set of machines that have currently been provisioned for this purpose. Detailed configuration can be carried out on AWS EC2 in order to derive the full benefit of Spark. The Spark team provides special EC2 AMIs (Amazon Machine Images) that can be utilized while running your Spark implementation on AWS. This may be tailored to a particular build or version of Spark, so these AMIs may not work for your specific use case if there is any custom modifications have been made to Spark.
The alternate option is to use Amazon’s Elastic Map Reduce (EMR) service. Amazon EMR is a web service that makes it easy to run Hadoop clusters using AWS resources such as Amazon EC2 virtual server instances. The enables the developer to launch clusters without having to maintain a data center of physical hardware. Amazon also follows pay per usage model, where in a flat fee does not need to be paid for the service, but only as per the developer’s usage. This is especially useful for applications that use the Spark framework. Spark stores all the data in memory due to which its CPU and memory requirements can vary depending on the workload. The developer can change the size of the cluster while running the EMR job as per the application’s needs. EMR also allows a change to the number of nodes in a cluster as Spark’s resource requirements change.
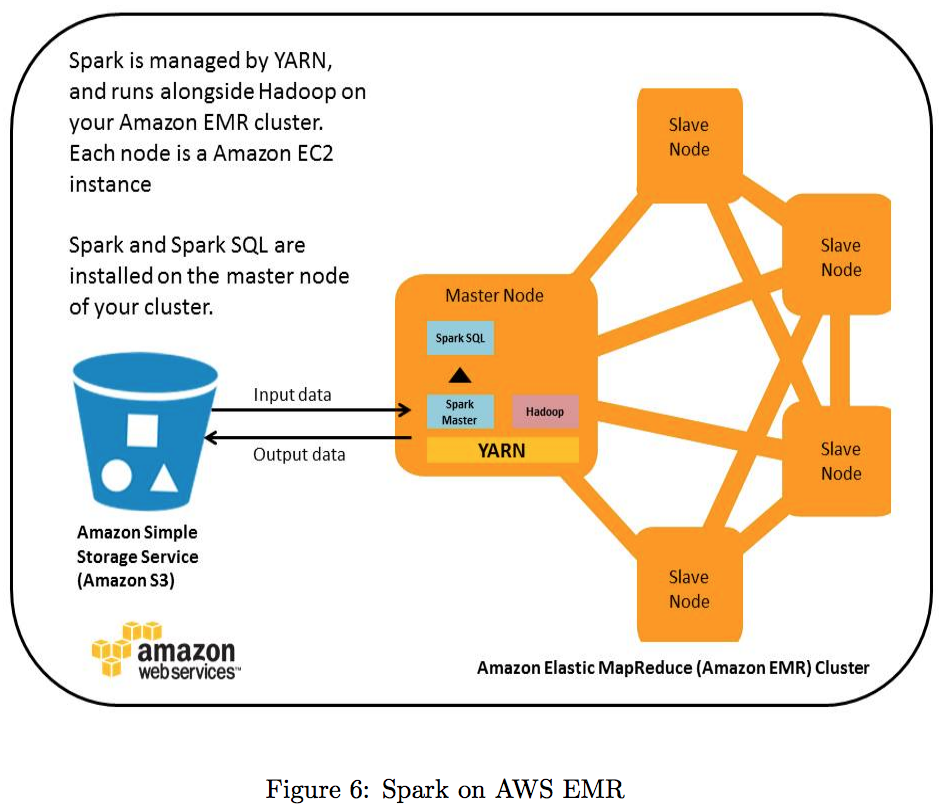
Figure 6 below illustrates running Spark on a Hadoop cluster managed by Amazon EMR. When a cluster is launched, Amazon EMR provisions virtual server instances from Amazon EC2. These can be used as an Amazon EMR bootstrap action to install Spark on the cluster. Spark on Amazon EMR can process data from an Amazon S3 (Simple Storage Service) bucket or stored in HDFS, and the results from these queries can also be persisted back to Amazon S3 or HDFS after analysis.
Example Applications using Spark:
Alternating Least Squares
A good example top demonstrate the usability of Spark is alternating least squares (ALS) algorithm. ALS is used for collaborative filtering problems, such as predicting users’ ratings for movies that they have not seen based on their movie rating history. The ALS algorithm is known to be CPU-intensive. Suppose that we wanted to predict the ratings of u users for m movies, and that we had a partially filled matrix R containing the known ratings for some user-movie pairs. ALS models R as the product of two matrices M and U of dimensions m ∗ k and k ∗ u respectively. This means that each user and each movie has a k-dimensional “feature vector” describing its characteristics, and a user’s rating for a movie is the dot product of its feature vector and the movie’s. ALS solves for M and U using the known ratings and then computes M ∗ U to predict the unknown ones. This is done using the following iterative process:
- Initialize M to a random value.
- Optimize U given M to minimize error on R.
- Optimize M given U to minimize error on R.
- Repeat steps 2 and 3 until convergence.
ALS can be parallelized by updating different users or movies on each node in
steps 2 and 3. However, because all of the steps use R, it is helpful to make R
a broadcast variable so that it does not get resent to each node on every step.
It could be observed that without using broadcast variables, the time to resend the ratings matrix R on each iteration dominated the job’s running time. Furthermore, with a naive implementation of broadcast (using HDFS or NFS), the broadcast time grew linearly with the number of nodes, limiting the scalability of the job. This was implemented using an application-level multicast system to mitigate this issue. But, in spite of a fast broadcast, resending R on each iteration is costly. Caching R in memory on the workers using a broadcast variable improved performance by 2.8x in an experiment with 5000 movies and 15000 users on a 30-node EC2 cluster.
References
- Spark MLlib documentation: https://spark.apache.org/docs/0.9.0/mllib-guide.html
- AWS documentation : http://aws.amazon.com/articles/4926593393724923
Figures:
Figure 6: http://aws.amazon.com/articles/4926593393724923